已經邁向第29天了,但我還在熟悉Nodejs的表面的感覺,
想在這倒數第二天做出有點技術的東西,
可是依我現在對Nodejs還沒有這麼熟悉上手,
所以今天這篇我參考了一個網站作者寫的程式來修改使用,
在此真的很感謝這位作者,在結尾也會放上網頁連結。
今天要實作的就是爬蟲,其實自己嘗試了幾天,但是依然做不出我想要的結果,
或許是我技術不成熟又選了網頁結構複雜的網站想抓取我想要的資訊。
先跟各位介紹原本我想要爬取颱風資訊的。

嘗試多次後,只顯示了一部分結果出來而已(哭…),
所以就換了一個網頁結構相對簡單的網站來抓取。選擇的是三立新聞網,
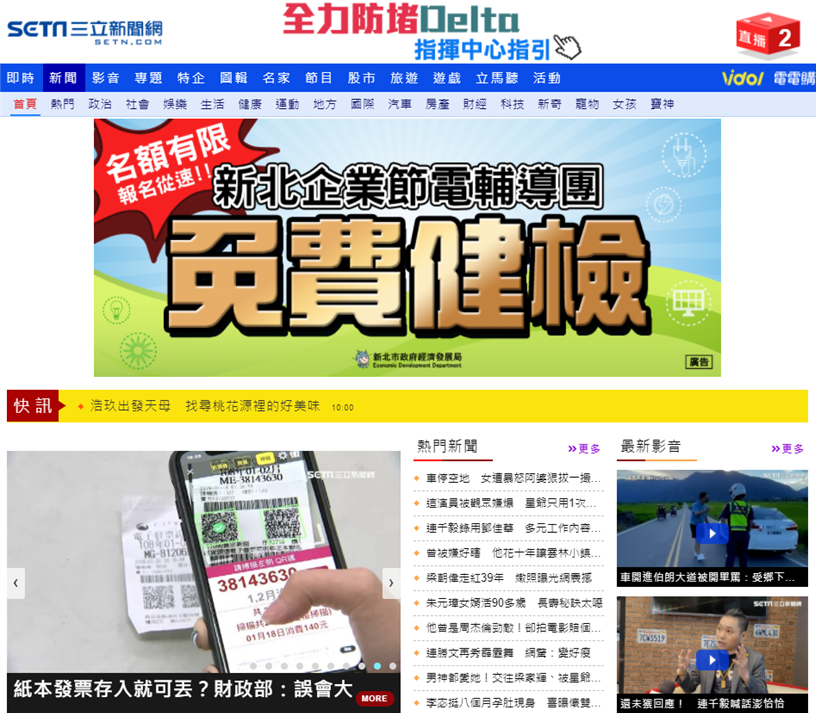
而我要抓取的部分就是熱門新聞這個部分,內容包括新聞標題與其連結。
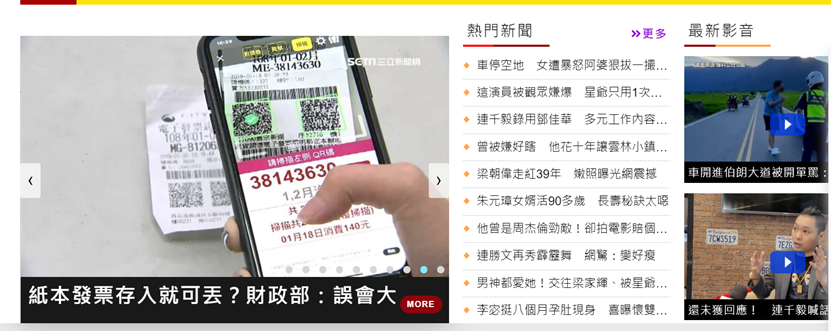
首先,先分析頁面,[右鍵]->[檢查],找到熱點新聞的區塊。
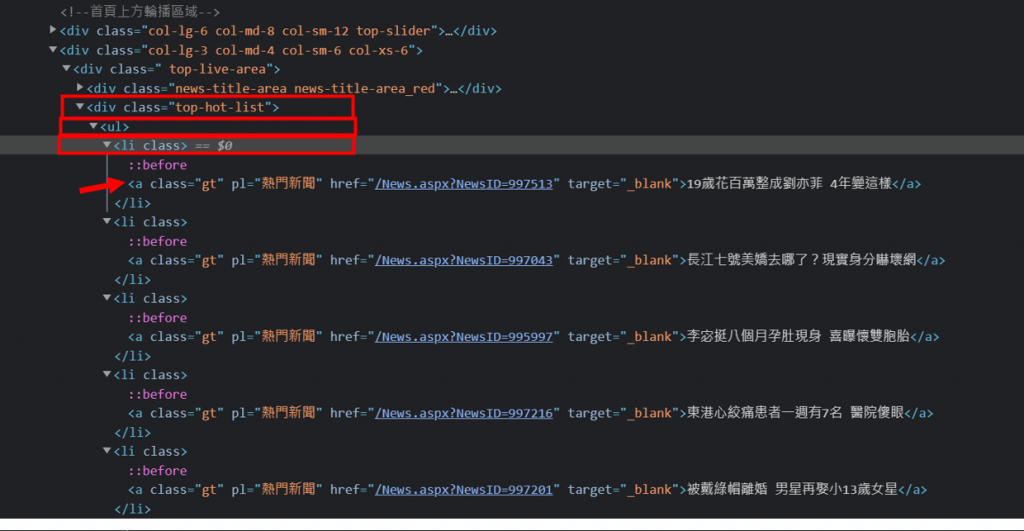

而我要抓取的就在 div.top-hot-list 中<ul>裡面所有的<li>標籤的<a>內容。
今天要用到的第三方模組有三個,
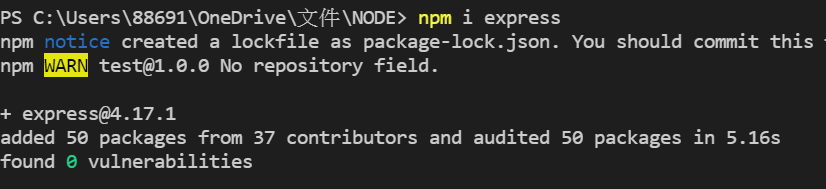
第一個先安裝express模組,在終端機輸入 npm i express
第二個安裝 superagent 模組,在終端機輸入 npm i superagent
第三個安裝cheerio模組,在終端機輸入 npm i cheerio。
安裝成功後,分別導入express、superagent、cheerio模組。
//導入模組
const express=require("express");
const app=express();
const superagent=require("superagent");
const cheerio=require("cheerio");
首先使用express模組來建立伺服器,
//建立伺服器
app.get("/",async(req,res,next)=>{
res.send(Keynews);
});
app.listen(3000);
再使用supperagent模組的get(),
放入指定的網址(三立新聞網),當成功實資料會指定給res。
//三立新聞網網址
superagent.get("https://www.setn.com/").end((err,res)=>
{
Keynews=getKeynews(res);
});
再來使用cheerio模組取得要抓取的資料,這個在爬蟲系統中,
除了一些Node核心模組外,cheerio也是重要的輔助模組之一。
先給予一個空的陣列名為Keynews,以便儲存數據。
並使用cheerio模組$的load()尋找在我指定的項目中要抓取的資料,
而我正是需要在div的top-live-area框架下面的<ul>之中的<li>標籤下的<a>的標題與連結。
取得資料後都存到Keynews陣列中,並回傳。
//開始取的資料
let getKeynews=(res)=>
{
let Keynews=[]; //設定一個空陣列
let $=cheerio.load(res.text); //$為cheerio.load()
// $("url#list-unstyled li span").each((idx,ele)=>
$("div.top-live-area ul li a").each((idx,elem)=>
{ //指定項目
let allnews={
title:$(elem).text(), //抓取新聞標題
href:$(elem).attr("href")//抓取新聞連結
};
Keynews.push(allnews);
});
return Keynews;
}
輸入 http://127.0.0.1:3000/, 查看結果
執行結果:
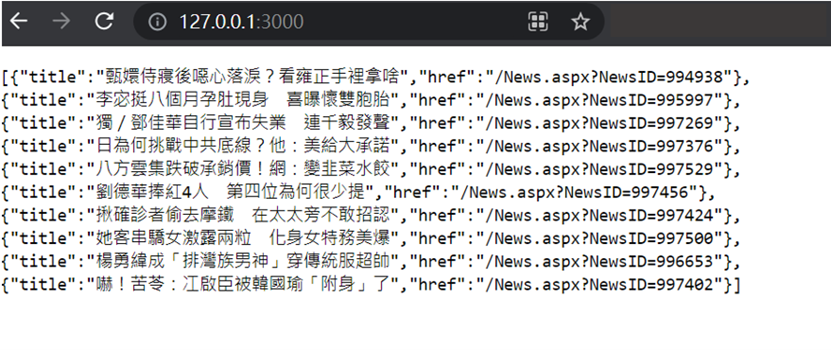
登愣!!!這樣一個簡易爬蟲系統就完成了!
雖然沒有很專業的爬蟲,但是能抓到資料,我也覺得很滿足了,
未來在繼續學習的話,相信我會再做出更專業的爬蟲系統的。
參考資料:
https://codertw.com/ios/20272/
最後倒數!!!!天啊你好棒!!!而且已經很厲害了真的!
齁齁沒有啦~但謝謝尼!!三十天來的鼓勵留言!!我要迎接最後一天了!!
尼也倒數了!!加油加油!!

